- Data Source Objects is a factory of connections to physical data sources.
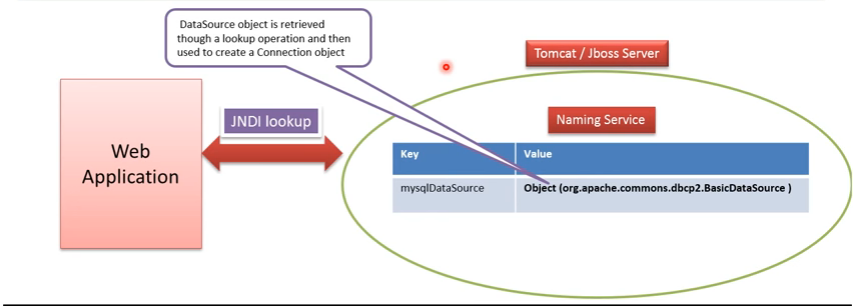
- To use datasource, We need to configure the data source in the naming service of JBoss or Tomacat. Webapplication can use JNDI lookup to get the datasource and using that data source we can create the connections.
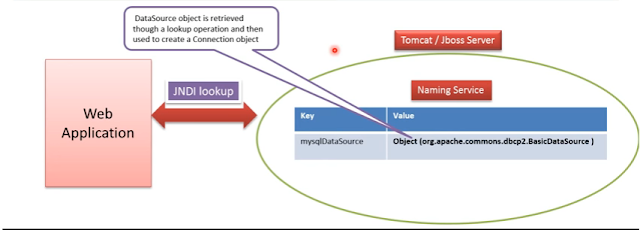
- The interface Datasource is packaged inside javx.sql package. Datasource Interface is imlemented by the driver vendor like mySql, Oracle etc.
- There are three types of implementations for Datasouce interface.
1. Basic Pooling Implementation:- Produces a standard connection object. The connection produced is idential to the connection produced by the DriverManager class.A basic DataSource implementation produces standard Connection objects that are not pooled or used in a distributed transaction.
2. Connection Pooling Implementation:- A DataSource implementation that supports connection pooling produces Connection objects that participate in connection pooling, that is, connections that can be recycled.
3. Distributed Transaction Implementation:- A DataSource implementation that supports distributed transactions produces Connection objects that can be used in a distributed transaction, that is, a transaction that accesses two or more DBMS servers.
- Advantages of DataSource Objects
1. Programmers no longer have to hard code the driver name or JDBC URL in their applications, which makes them more portable.
2. When the DataSource interface is implemented to work with a ConnectionPoolDataSource implementation, all of the connections produced by instances of that DataSource class will automatically be pooled connections.
3. when the DataSource implementation is implemented to work with an XADataSource class, all of the connections it produces will automatically be connections that can be used in a distributed transaction.
Tomcat DataSource JNDI
- To declare a JNDI DataSource for the MySQL database, create a Resource XML element with the following content:
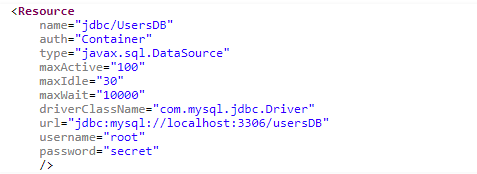
- Add this element inside the root element context tag in the context.xml file of tomcatThere are two places where the context.xml file can reside (create one if not exist):
1. Inside /META-INF directory of a web application
2. Inside $CATALINA_BASE/conf directory:
- Add the following declaration into the web.xml file:

- We can look up the configured JNDI DataSource using Java code as follows:
Context initContext = new InitialContext(); Context envContext = (Context) initContext.lookup("java:comp/env"); DataSource ds = (DataSource) envContext.lookup("jdbc/UsersDB"); Connection conn = ds.getConnection();
Interface
- Interface is a blueprint of a class and it contains only public abstract methods and staic final variables(contants)
- Sub classes able implemeting interface by implementing all nethods.
- Interfaces can be use when we need to achieve muliple inheritance because it supports multiple inheritance.

